LLM(大規模言語モデル)は、人工知能の分野で急速に発展している技術の一つです。
本記事では、LLMの基本概念から、その仕組み、進化の歴史、活用事例、そして今後の展望について詳しく解説します。
LLM(大規模言語モデル)とは?基本概念を解説
LLM(Large Language Model)とは、膨大なテキストデータを学習し、自然な文章を生成したり、質問に答えたりすることができるAIモデルです。
近年のAI技術の進歩により、LLMは人間に近い自然な言語処理を可能にしています。
この技術は、特に文章の自動生成、要約、翻訳、質問応答システムなど、多くの分野で活用されています。
また、LLMは単なるテキスト処理の枠を超え、コード生成やクリエイティブなコンテンツ作成、さらには医療や法務分野での知識サポートなど、専門的な領域にも応用が広がっています。
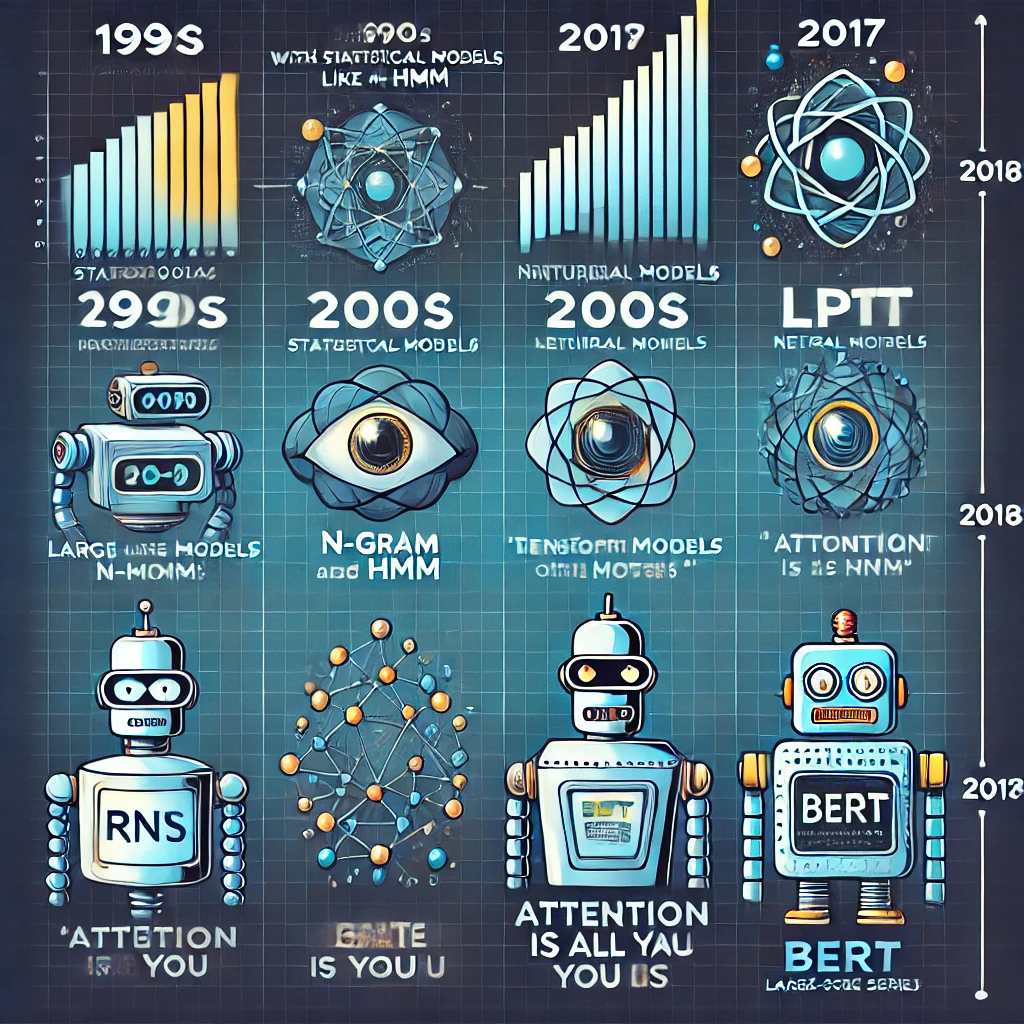
LLMの進化の歴史(統計的手法からTransformerへ)
| 年代 | 進化の段階 | 概要 |
|---|---|---|
| ~1990年代 | 統計的手法の時代 | n-gramモデルやHMMを用いて、単語の出現確率に基づく言語予測が行われていた。 |
| 2000年代 | ニューラルネットワークの導入 | RNN(再帰型ニューラルネットワーク)やLSTM(長短期記憶)が登場し、文脈の理解が向上した。 |
| 2017年 | Transformerの登場 | Googleの「Attention Is All You Need」により、全単語を同時に処理できるTransformerアーキテクチャが発表された。 |
| 2018年~ | 大規模LLMの時代 | GPTシリーズやBERTなどが登場し、パラメータ数が増大しながら高度な言語理解と生成が可能になった。 |
LLMの仕組み:Transformerと自己注意機構
LLMの核となる技術は、Transformerアーキテクチャです。
この技術の特徴は、文中の単語の関係性を「自己注意機構(Self-Attention)」を用いて解析する点にあります。
従来のRNNベースのモデルでは、時系列順に単語を処理するため、長い文脈を保持するのが難しいという課題がありました。
しかし、Transformerは全ての単語を同時に処理し、それぞれの単語間の関連性を考慮することで、より正確な意味理解を可能にしています。
自己注意機構は、各単語が他の単語とどれだけ関連しているかをスコア化し、それを加重平均することで、適切な文脈を保持します。
これにより、従来のモデルよりも長文の処理や翻訳などのタスクで優れたパフォーマンスを発揮します。
また、トレーニング時には膨大なデータを学習するため、多様な言語表現に対応できる点も大きな特徴です。
代表的なLLMの種類(GPT・BERT・Claude など)
現在、LLMにはさまざまな種類があり、それぞれ異なる特性を持っています。
GPT(Generative Pre-trained Transformer)は、OpenAIが開発したモデルで、主にテキスト生成に優れています。
このモデルは、人間のような自然な文章を生成することが可能であり、創作活動やチャットボットなどに幅広く活用されています。
一方、BERT(Bidirectional Encoder Representations from Transformers)はGoogleが開発したモデルで、双方向の文脈理解に特化しています。
BERTは、前後の文脈を同時に考慮することで、より高度な文章理解を実現しています。
検索エンジンの精度向上や質問応答システムの改善に大きく貢献しています。
また、ClaudeはAnthropic社が開発したLLMで、安全性を重視した設計となっています。
倫理的な問題を考慮し、不適切な出力を抑える機能が強化されており、企業向けの導入が進んでいます。
LLMの活用事例(検索エンジン・翻訳・コンテンツ生成)
LLMは、さまざまな分野で活用されています。
例えば、検索エンジンではGoogleやBingの検索アルゴリズムに組み込まれ、より適切な検索結果を提供するのに役立っています。
また、翻訳分野では、LLMを活用した自動翻訳システムが精度の高い言語変換を可能にしています。
さらに、コンテンツ生成の分野では、記事やブログ、プログラムコードの自動作成が可能となり、ライティングの効率が大幅に向上しました。
カスタマーサポートにおいても、AIチャットボットが導入され、迅速かつ的確な対応を実現しています。
教育分野では、学習支援ツールとして活用され、生徒一人ひとりに適したカリキュラムの提供が可能になっています。
LLMの課題と今後の展望
LLMには多くの可能性がありますが、一方でいくつかの課題も存在します。
例えば、モデルのトレーニングには膨大な計算資源が必要であり、そのコストは非常に高いものとなっています。
また、学習データに偏りがある場合、モデルがバイアスを含んだ出力をする可能性があり、公平性の確保が重要な課題となっています。
LLMの技術は日々進化しており、今後ますます多くの分野で活用されることでしょう。
その可能性を最大限に活かすためには、技術の理解と適切な運用が重要となります。


